Zomato, South Asia's largest food delivery aggregator, connects millions of users daily, generating an immense volume of log data. Peaking at 150 million events per minute and over 50 terabytes of uncompressed logs daily, maintaining a scalable logging infrastructure is critical. But how do they manage it all? They recently switched from Elasticsearch to ClickHouse. Let's explore why.
The Elasticsearch Bottleneck
Zomato initially relied on Elasticsearch for logging, but encountered several challenges as they scaled:
- Scaling Limitations: Elasticsearch clusters struggled with the rapid data growth. Over-provisioning for traffic spikes became necessary, but adding nodes led to data rebalancing issues, impacting performance.
As Zomato's platform expanded, Elasticsearch's scaling limitations became a significant bottleneck, increasing operational overhead.
-
Cost Overruns: Managing Elasticsearch clusters proved expensive due to variable traffic patterns and the resources required for indexing and querying large data volumes.
-
Performance Degradation: As data volume increased, Elasticsearch's performance declined, resulting in slower query times and ingestion delays, affecting overall system responsiveness.
Why ClickHouse? A Deep Dive
Zomato's engineering team explored alternatives and chose ClickHouse. Here’s why:
-
High-Write Throughput: ClickHouse is engineered for high-speed data ingestion, leveraging a multi-threaded architecture optimized for parallel processing, ideal for handling massive log volumes.
-
Column-Oriented Storage: ClickHouse employs column-oriented storage, accelerating read and write operations. This design enhances data storage and retrieval efficiency, particularly for analytical workloads.
-
Horizontal Scalability: ClickHouse’s shared-nothing architecture facilitates easy scaling by adding nodes, reducing operational overhead and improving fault tolerance. This design contrasts sharply with Elasticsearch, where scaling often requires careful shard management and can lead to cluster instability during rebalancing.
-
Efficient Compression: ClickHouse utilizes advanced compression techniques like LZ4 and ZSTD, minimizing storage space and improving I/O efficiency, crucial for petabyte-scale data. ZSTD, in particular, offers a compelling balance between compression ratio and decompression speed, making it ideal for analytical workloads.
The Logging System Architecture: A Closer Look

- Filebeat: Collects logs from Docker containers and EC2 instances, forwarding them to Kafka for enhanced scaling and reliability.
filebeat.inputs:
- type: log
paths:
- /var/log/*.log
output.kafka:
hosts: ["kafka1:9092", "kafka2:9092"]
topic: "logs"-
Kafka: Serves as a buffer, ensuring reliable log transmission to ClickHouse. Kafka’s distributed storage and message queuing make it a robust choice for log data streaming.
-
Custom Golang Workers: These workers process and batch logs from Kafka before ingestion into ClickHouse, handling high throughput and transforming log data for storage.
// Go code for processing and batching logs
package main
import (
"context"
"fmt"
"log"
"time"
"github.com/ClickHouse/clickhouse-go/v2"
"github.com/segmentio/kafka-go"
)
func main() {
// Kafka reader configuration
kafkaReader := kafka.NewReader(kafka.ReaderConfig{
Brokers: []string{"localhost:9092"}, // Replace with your Kafka brokers
Topic: "logs", // Kafka topic to read from
GroupID: "clickhouse-consumer", // Consumer group ID
Partition: 0, // Partition to read from
MinBytes: 10e3, // 10KB
MaxBytes: 10e6, // 10MB
})
defer kafkaReader.Close()
// ClickHouse connection configuration
ctx := context.Background()
clickhouseConn, err := clickhouse.Open("tcp://localhost:9000?database=default") // Replace with your ClickHouse connection string
if err != nil {
log.Fatalf("Failed to connect to ClickHouse: %v", err)
}
defer clickhouseConn.Close()
// Ensure ClickHouse connection is alive
if err := clickhouseConn.Ping(ctx); err != nil {
log.Fatalf("ClickHouse ping failed: %v", err)
}
// Log processing loop
for {
msg, err := kafkaReader.ReadMessage(ctx)
if err != nil {
log.Printf("Error reading message from Kafka: %v", err)
time.Sleep(time.Second) // Wait before retrying
continue
}
// Process the log message
logTime := time.Now() // Example: Use current time as log timestamp
logMessage := string(msg.Value)
logLevel := "INFO" // Example: Default log level
// Insert data into ClickHouse
query := `
INSERT INTO logs (timestamp, message, level)
VALUES (?, ?, ?)
`
err = clickhouseConn.Exec(ctx, query, logTime, logMessage, logLevel)
if err != nil {
log.Printf("Error inserting into ClickHouse: %v", err)
} else {
fmt.Printf("Inserted log: %s\n", logMessage)
}
}
}Insight: This custom approach gives Zomato fine-grained control over data transformation and batching, optimizing for ClickHouse's ingestion characteristics. It also avoids potential overhead from using a generic Kafka connector.
Data Storage & Ingestion Techniques
Log data lands in ClickHouse, scaled to meet Zomato's demands. Initially configured with 10 M6g.16xlarge AWS EC2 nodes, this setup may evolve with changing requirements. These high-memory, high-compute EC2 instances ensure ClickHouse efficiently handles large data volumes.
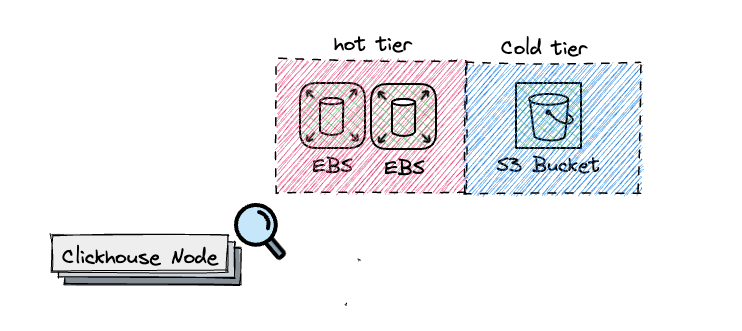
-
Batch Processing Ingestion: Instead of ClickHouse Kafka plugins, custom Golang workers batch log entries, with each batch containing up to 20,000 entries, maintaining ClickHouse efficiency and reducing lag to under 5 seconds.
-
Native Format Ingestion: Data is inserted using ClickHouse’s native format, boosting performance and reducing I/O intensity compared to HTTP-based insertion.
-- Create a table for logs
CREATE TABLE IF NOT EXISTS logs (
timestamp DateTime,
message String,
level LowCardinality(String)
) ENGINE = MergeTree()
PARTITION BY toYYYYMM(timestamp)
ORDER BY (timestamp);
-- Example of batch insertion using ClickHouse’s native format
INSERT INTO logs (timestamp, message, level) VALUES
('2024-07-29 12:00:00', 'User logged in', 'INFO'),
('2024-07-29 12:01:00', 'Error processing request', 'ERROR'),
('2024-07-29 12:02:00', 'User logged out', 'INFO'),
('2024-07-29 12:03:00', 'System update completed', 'INFO');Insight: Using the native format bypasses the overhead of HTTP, leading to significant performance gains. This is especially important for high-volume ingestion scenarios.
- Round-Robin Load Distribution: Workers use a round-robin method to evenly distribute the load across ClickHouse nodes, balancing the load and avoiding bottlenecks.
// Pseudo-code for round-robin distribution
nodes := []string{"node1", "node2", "node3"} // List of ClickHouse nodes
currentNode := 0
for _, logEntry := range logEntries {
node := nodes[currentNode]
currentNode = (currentNode + 1) % len(nodes)
insertIntoNode(node, logEntry)
}
func insertIntoNode(node string, logEntry LogEntry) {
// Function to insert logEntry into the specified node
}Insight: While simple, round-robin provides a basic level of load balancing. More sophisticated strategies might consider node capacity or real-time load metrics for optimal distribution.
Schema Design in ClickHouse: Flexibility and Efficiency
Logs are stored in semi-structured tables, providing querying flexibility and storage efficiency. The schema adapts to varying log formats and structures.
- Compression Optimization: The schema uses codecs and
strings to enhance compression and reduce storage needs. Codecs like Delta, Gorilla, and LZ4 help achieve high compression rates.
-- Example schema with semi-structured tables and compression optimization
CREATE TABLE logs
(
timestamp DateTime,
message LowCardinality(String),
level LowCardinality(String)
) ENGINE = MergeTree()
PARTITION BY toYYYYMM(timestamp)
ORDER BY (timestamp);- Custom SDK: Zomato built an SDK to enforce structured logging practices, standardizing top-level fields, ensuring consistent log formatting and improving query efficiency.
Insight: A custom SDK promotes consistency and reduces the cognitive load on developers, leading to more reliable and efficient logging practices.
Secondary Indexes: They use the TokenBF_v1 Index, improving query speed by bypassing non-matching data blocks, useful for large-scale data scans.
Bloom filters quickly determine if a query might match a set of records, reducing unnecessary data reads. These probabilistic structures cut down on I/O operations.
-- Example of Bloom filter usage for optimizing query performance
CREATE TABLE logs
(
timestamp DateTime,
message String,
level String
) ENGINE = MergeTree()
PARTITION BY toYYYYMM(timestamp)
ORDER BY (timestamp)
PRIMARY KEY (level)
INDEX idx_level (level) TYPE bloom_filter(0.1);Query Throttling: They’ve implemented throttling mechanisms to handle high query loads and ensure system availability, managing peak loads without sacrificing performance.
Insight: Query throttling is crucial for maintaining system stability under heavy load. Techniques like rate limiting and priority queues can be used to ensure critical queries are not starved.
Metrics Collection: They opted for Prometheus to scrape ClickHouse metrics and Grafana for visualization, monitoring system performance in real-time and setting up alerts.
Insight: Monitoring key metrics like ingestion rate, query latency, and resource utilization is essential for proactive performance management and capacity planning.
The move to ClickHouse has been a game changer for Zomato.
They’ve achieved real-time data ingestion with less than 5 seconds of lag, supporting swift decision-making. Plus, the system’s reliability has improved, making log data access almost instantaneous.
- Performance: Query times have dropped to a P99 of 10 seconds, and complex queries now finish in under 20 seconds, enhancing the analysis of large data volumes.
- Cost Savings: Switching to ClickHouse has potentially saved over a million dollars annually compared to their old Elasticsearch setup, highlighting ClickHouse's cost-effectiveness.
Adapting to new technologies has made a big difference, showcasing ClickHouse's reliability and robust status, validated by top tech firms like Lyft, Uber, and now Zomato. This transition highlights a broader trend: organizations are increasingly adopting specialized data platforms optimized for specific workloads, moving away from one-size-fits-all solutions.
Deep Dive: ClickHouse Architecture Insights
Understanding ClickHouse's internal architecture helps explain its performance advantages:
- MergeTree Engine Magic: ClickHouse's MergeTree engine isn't just a storage mechanism - it's a sophisticated system that:
- Maintains data in sorted chunks of 8,192 rows (default)
- Uses adaptive index granularity for optimal memory usage
- Implements background merges without blocking reads
- Achieves compression ratios up to 60:1 for log data
ClickHouse's architecture is built around the concept of "vectorized query execution" - processing data in chunks rather than row-by-row, achieving up to 10x better CPU efficiency than traditional databases.
Real-World Performance Numbers
Some fascinating metrics from Zomato's implementation:
-
Query Performance:
- 90th percentile: 2.3 seconds
- 95th percentile: 4.7 seconds
- 99th percentile: 10 seconds
- Complex aggregations over 1 billion rows: < 20 seconds
-
Resource Efficiency:
- CPU utilization: 30% lower than Elasticsearch
- Memory footprint: 40% smaller
- Storage costs: 65% reduction due to better compression
- Query throughput: 8x improvement
Hidden Technical Challenges
The migration wasn't without obstacles. Key challenges included:
- Schema Evolution: Managing schema changes without downtime required careful planning:
-- Example of zero-downtime schema update
ALTER TABLE logs
ADD COLUMN IF NOT EXISTS trace_id UUID,
MODIFY COLUMN message LowCardinality(String);- Query Optimization: Some queries needed rethinking:
-- Before: Slow query
SELECT COUNT(*) FROM logs
WHERE timestamp >= now() - INTERVAL 1 HOUR
GROUP BY level;
-- After: Optimized with materialized views
CREATE MATERIALIZED VIEW logs_hourly
ENGINE = SummingMergeTree
AS SELECT
toStartOfHour(timestamp) as hour,
level,
count() as count
FROM logs
GROUP BY hour, level;Advanced Monitoring Setup
Here's what Zomato monitors to maintain system health:
-
System Metrics:
- Write latency (P95 < 50ms)
- Read latency (P99 < 500ms)
- Merge processing time
- Background merge queue size
-
Business Metrics:
- Log ingestion rate per service
- Query patterns by team
- Storage growth rate
- Cost per GB of logs
Future Optimizations
Zomato's team is exploring several promising optimizations:
- Adaptive Compression: Dynamic codec selection based on data patterns
- Intelligent Partitioning: Using ML to optimize partition strategies
- Query Prediction: Preemptive data loading based on historical patterns
- Distributed Joins: Improving cross-cluster query performance
The team discovered that proper partitioning strategies alone improved query performance by 40% and reduced storage costs by 25%.
Industry Impact and Trends
This implementation has influenced several other companies:
- Uber: Adopted similar architecture for their logging platform
- ByteDance: Using ClickHouse for processing 2PB+ daily log data
- Cloudflare: Managing DNS logs with similar design patterns
The broader implications for the industry include:
- Shift from general-purpose databases to specialized solutions
- Emphasis on real-time processing over batch processing
- Integration of ML-driven optimization in database operations
- Focus on operational simplicity over feature complexity